
Fuzzy string Matching using fuzzywuzzyR and the reticulate package in R
13 Apr 2017I recently released an (other one) R package on CRAN - fuzzywuzzyR - which ports the fuzzywuzzy python library in R. “fuzzywuzzy does fuzzy string matching by using the Levenshtein Distance to calculate the differences between sequences (of character strings).”
There is no big news here as in R already exist similar packages such as the stringdist package. Why then creating the package? Well, I intend to participate in a recently launched kaggle competition and one popular method to build features (predictors) is fuzzy string matching as explained in this blog post. My (second) aim was to use the (newly released from Rstudio) reticulate package, which “provides an R interface to Python modules, classes, and functions” and makes the process of porting python code in R not cumbersome.
First, I’ll explain the functionality of the fuzzywuzzyR package and then I’ll give some examples on how to take advantage of the reticulate package in R.
UPDATE 26-07-2018: A Singularity image file is available in case that someone intends to run fuzzywuzzyR on Ubuntu Linux (locally or in a cloud instance) with all package requirements pre-installed. This allows the user to utilize the fuzzywuzzyR package without having to spend time on the installation process.
fuzzywuzzyR
The fuzzywuzzyR package includes R6-classes / functions for string matching,
classes
| FuzzExtract | FuzzMatcher | FuzzUtils | SequenceMatcher |
|---|---|---|---|
| Extract() | Partial_token_set_ratio() | Full_process() | ratio() |
| ExtractBests() | Partial_token_sort_ratio() | Make_type_consistent() | quick_ratio() |
| ExtractWithoutOrder() | Ratio() | Asciidammit() | real_quick_ratio() |
| ExtractOne() | QRATIO() | Asciionly() | get_matching_blocks() |
| WRATIO() | Validate_string() | get_opcodes() | |
| UWRATIO() | |||
| UQRATIO() | |||
| Token_sort_ratio() | |||
| Partial_ratio() | |||
| Token_set_ratio() |
functions
GetCloseMatches()
The following code chunks / examples are part of the package documentation and give an idea on what can be done with the fuzzywuzzyR package,
FuzzExtract
Each one of the methods in the FuzzExtract class takes a character string and a character string sequence as input ( except for the Dedupe method which takes a string sequence only ) and given a processor and a scorer it returns one or more string match(es) and the corresponding score ( in the range 0 - 100 ). Information about the additional parameters (limit, score_cutoff and threshold) can be found in the package documentation,
library(fuzzywuzzyR)
word = "new york jets"
choices = c("Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys")
#------------
# processor :
#------------
init_proc = FuzzUtils$new() # initialization of FuzzUtils class to choose a processor
PROC = init_proc$Full_process # processor-method
PROC1 = tolower # base R function ( as an example for a processor )
#---------
# scorer :
#---------
init_scor = FuzzMatcher$new() # initialization of the scorer class
SCOR = init_scor$WRATIO # choosen scorer function
init <- FuzzExtract$new() # Initialization of the FuzzExtract class
init$Extract(string = word, sequence_strings = choices, processor = PROC, scorer = SCOR)
# example output
[[1]]
[[1]][[1]]
[1] "New York Jets"
[[1]][[2]]
[1] 100
[[2]]
[[2]][[1]]
[1] "New York Giants"
[[2]][[2]]
[1] 79
[[3]]
[[3]][[1]]
[1] "Atlanta Falcons"
[[3]][[2]]
[1] 29
[[4]]
[[4]][[1]]
[1] "Dallas Cowboys"
[[4]][[2]]
[1] 22
# extracts best matches (limited to 2 matches)
init$ExtractBests(string = word, sequence_strings = choices, processor = PROC1,
scorer = SCOR, score_cutoff = 0L, limit = 2L)
[[1]]
[[1]][[1]]
[1] "New York Jets"
[[1]][[2]]
[1] 100
[[2]]
[[2]][[1]]
[1] "New York Giants"
[[2]][[2]]
[1] 79
# extracts matches without keeping the output order
init$ExtractWithoutOrder(string = word, sequence_strings = choices, processor = PROC,
scorer = SCOR, score_cutoff = 0L)
[[1]]
[[1]][[1]]
[1] "Atlanta Falcons"
[[1]][[2]]
[1] 29
[[2]]
[[2]][[1]]
[1] "New York Jets"
[[2]][[2]]
[1] 100
[[3]]
[[3]][[1]]
[1] "New York Giants"
[[3]][[2]]
[1] 79
[[4]]
[[4]][[1]]
[1] "Dallas Cowboys"
[[4]][[2]]
[1] 22
# extracts first result
init$ExtractOne(string = word, sequence_strings = choices, processor = PROC,
scorer = SCOR, score_cutoff = 0L)
[[1]]
[1] "New York Jets"
[[2]]
[1] 100
The dedupe method removes duplicates from a sequence of character strings using fuzzy string matching,
duplicat = c('Frodo Baggins', 'Tom Sawyer', 'Bilbo Baggin', 'Samuel L. Jackson',
'F. Baggins', 'Frody Baggins', 'Bilbo Baggins')
init$Dedupe(contains_dupes = duplicat, threshold = 70L, scorer = SCOR)
[1] "Frodo Baggins" "Samuel L. Jackson" "Bilbo Baggins" "Tom Sawyer"
FuzzMatcher
Each one of the methods in the FuzzMatcher class takes two character strings (string1, string2) as input and returns a score ( in range 0 to 100 ). Information about the additional parameters (force_ascii, full_process and threshold) can be found in the package documentation,
s1 = "Atlanta Falcons"
s2 = "New York Jets"
init = FuzzMatcher$new() initialization of FuzzMatcher class
init$Partial_token_set_ratio(string1 = s1, string2 = s2, force_ascii = TRUE, full_process = TRUE)
# example output
[1] 31
init$Partial_token_sort_ratio(string1 = s1, string2 = s2, force_ascii = TRUE, full_process = TRUE)
[1] 31
init$Ratio(string1 = s1, string2 = s2)
[1] 21
init$QRATIO(string1 = s1, string2 = s2, force_ascii = TRUE)
[1] 29
init$WRATIO(string1 = s1, string2 = s2, force_ascii = TRUE)
[1] 29
init$UWRATIO(string1 = s1, string2 = s2)
[1] 29
init$UQRATIO(string1 = s1, string2 = s2)
[1] 29
init$Token_sort_ratio(string1 = s1, string2 = s2, force_ascii = TRUE, full_process = TRUE)
[1] 29
init$Partial_ratio(string1 = s1, string2 = s2)
[1] 23
init$Token_set_ratio(string1 = s1, string2 = s2, force_ascii = TRUE, full_process = TRUE)
[1] 29
FuzzUtils
The FuzzUtils class includes a number of utility methods, from which the Full_process method is from greater importance as besides its main functionality it can also be used as a secondary function in some of the other fuzzy matching classes,
s1 = 'Frodo Baggins'
init = FuzzUtils$new()
init$Full_process(string = s1, force_ascii = TRUE)
# example output
[1] "frodo baggins"
GetCloseMatches
The GetCloseMatches method returns a list of the best “good enough” matches. The parameter string is a sequence for which close matches are desired (typically a character string), and sequence_strings is a list of sequences against which to match the parameter string (typically a list of strings).
vec = c('Frodo Baggins', 'Tom Sawyer', 'Bilbo Baggin')
str1 = 'Fra Bagg'
GetCloseMatches(string = str1, sequence_strings = vec, n = 2L, cutoff = 0.6)
[1] "Frodo Baggins"
SequenceMatcher
The SequenceMatcher class is based on difflib which comes by default installed with python and includes the following fuzzy string matching methods,
s1 = ' It was a dark and stormy night. I was all alone sitting on a red chair.'
s2 = ' It was a murky and stormy night. I was all alone sitting on a crimson chair.'
init = SequenceMatcher$new(string1 = s1, string2 = s2)
init$ratio()
[1] 0.9127517
init$quick_ratio()
[1] 0.9127517
init$real_quick_ratio()
[1] 0.966443
The get_matching_blocks and get_opcodes return triples and 5-tuples describing matching subsequences. More information can be found in the Python’s difflib module and in the fuzzywuzzyR package documentation.
A last think to note here is that the mentioned fuzzy string matching classes can be parallelized using the base R parallel package. For instance, the following MCLAPPLY_RATIOS function can take two vectors of character strings (QUERY1, QUERY2) and return the scores for each method of the FuzzMatcher class,
MCLAPPLY_RATIOS = function(QUERY1, QUERY2, class_fuzz = 'FuzzMatcher', method_fuzz = 'QRATIO', threads = 1, ...) {
init <- eval(parse(text = paste0(class_fuzz, '$new()')))
METHOD = paste0('init$', method_fuzz)
if (threads == 1) {
res_qrat = lapply(1:length(QUERY1), function(x) do.call(eval(parse(text = METHOD)), list(QUERY1[[x]], QUERY2[[x]], ...)))}
else {
res_qrat = parallel::mclapply(1:length(QUERY1), function(x) do.call(eval(parse(text = METHOD)), list(QUERY1[[x]], QUERY2[[x]], ...)),
mc.cores = threads)
}
return(res_qrat)
}
query1 = c('word1', 'word2', 'word3')
query2 = c('similarword1', 'similar_word2', 'similarwor')
quer_res = MCLAPPLY_RATIOS(query1, query2, class_fuzz = 'FuzzMatcher', method_fuzz = 'QRATIO', threads = 1)
unlist(quer_res)
# example output
[1] 59 56 40
reticulate package
My personal opinion is that the newly released reticulate package is good news (for all R-users with minimal knowledge of python) and bad news (for package maintainers whose packages do not cover the full spectrum of a subject in comparison to an existing python library) at the same time. I’ll explain this in the following two examples.
As an R user I’d always like to have a truncated svd function similar to the one of the sklearn python library. So, now in R using the reticulate package and the mnist data set one can do,
reticulate::py_module_available('sklearn') # check that 'sklearn' is available in your OS
[1] TRUE
dim(mnist) # after downloading and opening the data from the previous link
70000 785
mnist = as.matrix(mnist) # convert to matrix
trunc_SVD = reticulate::import('sklearn.decomposition')
res_svd = trunc_SVD$TruncatedSVD(n_components = 100L, n_iter = 5L, random_state = 1L)
res_svd$fit(mnist)
# TruncatedSVD(algorithm='randomized', n_components=100, n_iter=5,
# random_state=1, tol=0.0)
out_svd = res_svd$transform(mnist)
str(out_svd)
# num [1:70000, 1:100] 1752 1908 2289 2237 2236 ...
class(out_svd)
# [1] "matrix"
to receive the desired output ( a matrix with 70000 rows and 100 columns (components) ).
As a package maintainer, I do receive from time to time e-mails from users of my packages. In one of them a user asked me if the hog function of the OpenImageR package is capable of plotting the hog features. Actually not, but now an R-user can, for instance, use the scikit-image python library to plot the hog-features using the following code chunk,
reticulate::py_module_available("skimage") # check that 'sklearn' is available in your OS
# [1] TRUE
feat <- reticulate::import("skimage.feature") # import module
data_sk <- reticulate::import("skimage.data") # import data
color <- reticulate::import("skimage.color") # import module to plot
tmp_im = data_sk$astronaut() # import specific image data ('astronaut')
dim(tmp_im)
# [1] 512 512 3
image = color$rgb2gray(tmp_im) # convert to gray
dim(image)
# [1] 512 512
res = feat$hog(image, orientations = 8L, pixels_per_cell = c(16L, 16L), cells_per_block = c(1L, 1L), visualise=T)
str(res)
# List of 2
# $ : num [1:8192(1d)] 1.34e-04 1.53e-04 6.68e-05 9.19e-05 7.93e-05 ...
# $ : num [1:512, 1:512] 0 0 0 0 0 0 0 0 0 0 ...
OpenImageR::imageShow(res[[2]]) # using the OpenImageR to plot the data
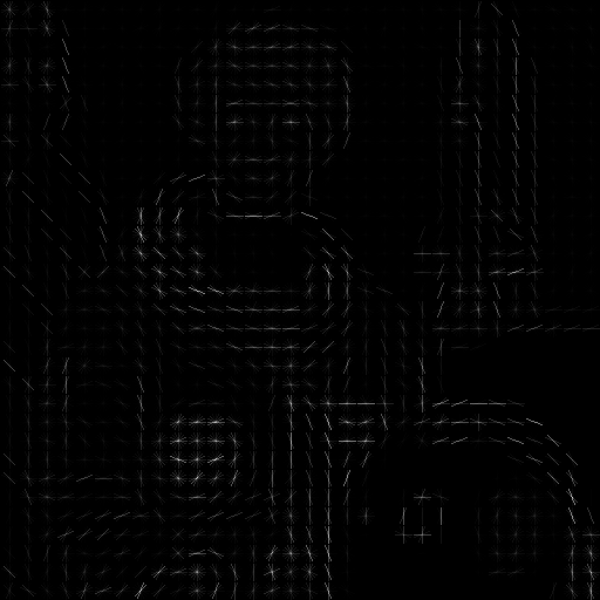
As a final word, I think that the reticulate package, although not that popular yet, it will make a difference in the R-community.
The README.md file of the fuzzywuzzyR package includes the SystemRequirements and detailed installation instructions for each OS.
An updated version of the fuzzywuzzyR package can be found in my Github repository and to report bugs/issues please use the following link, https://github.com/mlampros/fuzzywuzzyR/issues.